AI can drastically accelerate sustainability work—but only if its outputs are reliable enough for audit-grade emissions measurement. Generic AI lacks the context and training to be rigorous and transparent enough for sustainability purposes, and sustainability teams have had trouble evaluating sustainability AI to benchmark quality and effectiveness. Recently, though, benchmarks have emerged against which AI can be measured, evaluated, and fine-tuned.
When Amazon published the Parakeet dataset for AI-powered emissions factor matching, it was an important step forward for the field. Parakeet is a benchmark dataset: think of it like a test, plus an answer key. Benchmark datasets like Parakeet give the industry a shared way to measure performance and give buyers concrete evaluation methods that go beyond relying on vague claims of “AI-powered accuracy.”
We tested Watershed’s AI-powered auto-mapper on Parakeet, which matches messy procurement materials to the best-fit emissions factors. Our auto-mapper achieved 98.9% defensible mappings on the Parakeet benchmark dataset. Beyond strong performance, our climate scientists also identified places where the benchmark’s “answer key” could be improved.
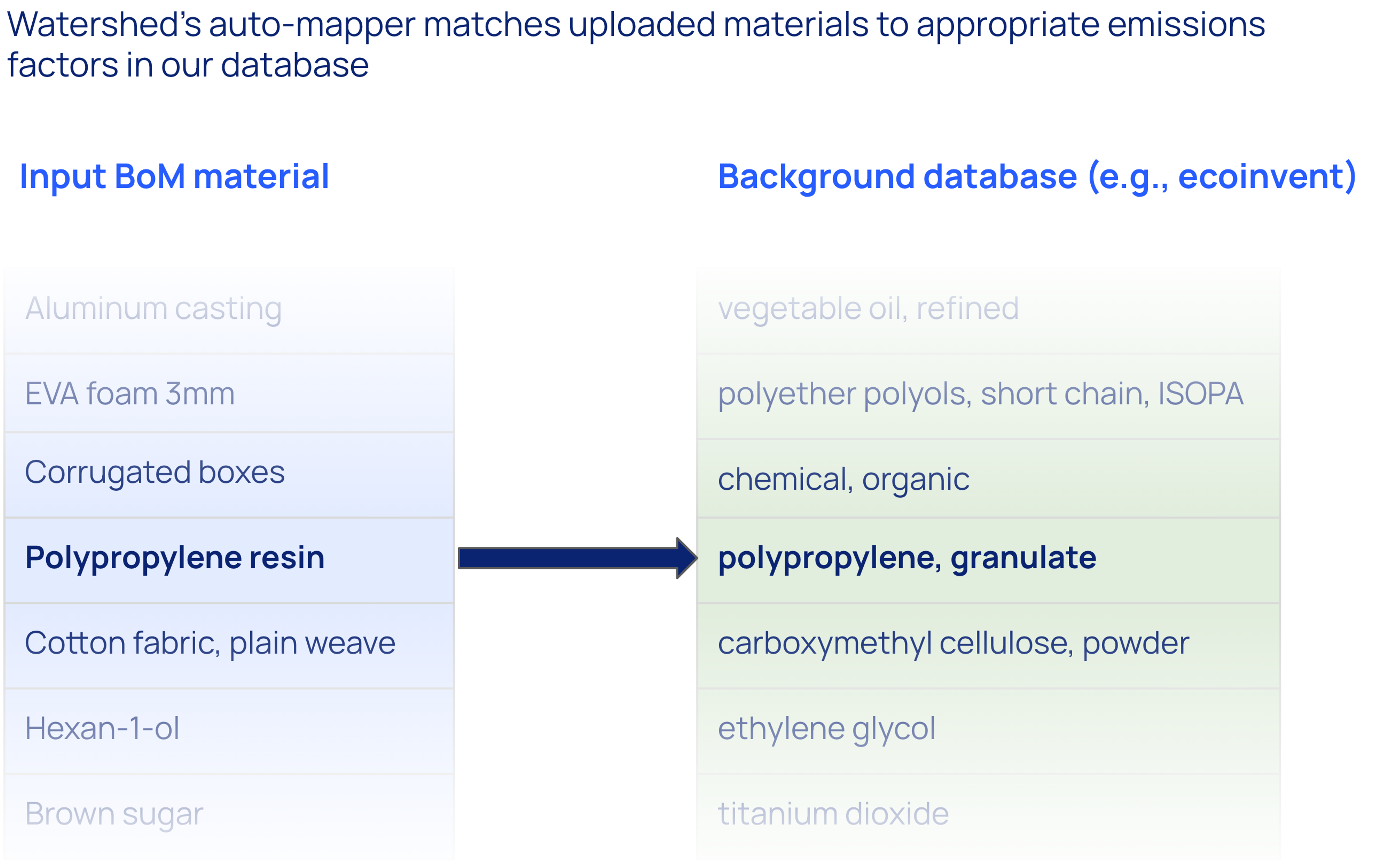
Watershed’s AI-powered auto-mapper maps companies' thousands of materials to best-fit emissions factors in moments
Companies measuring their supply chain emissions (Scope 3.1) typically purchase thousands or tens of thousands of distinct goods (also known as materials). To get activity-based measurements, each material needs to be mapped to an emission factor from lifecycle inventory emissions factor databases like ecoinvent.
Historically, that mapping process was time-consuming and error prone. An expert practitioner could easily take 10 minutes mapping each material (often with vague names that require research, plus subjective decision-making to decide if, for example, purchased aluminium should be mapped to wrought aluminium alloy versus cast aluminium alloy). For a company with 40,000 purchased materials, that process would take months.
Watershed’s auto-mapper automates this process, mapping everything a company purchases to best-fit emissions factors in moments. The system scores how similar the material and emissions factor are, and how well that emissions factor represents the likely real-world emissions of the material.
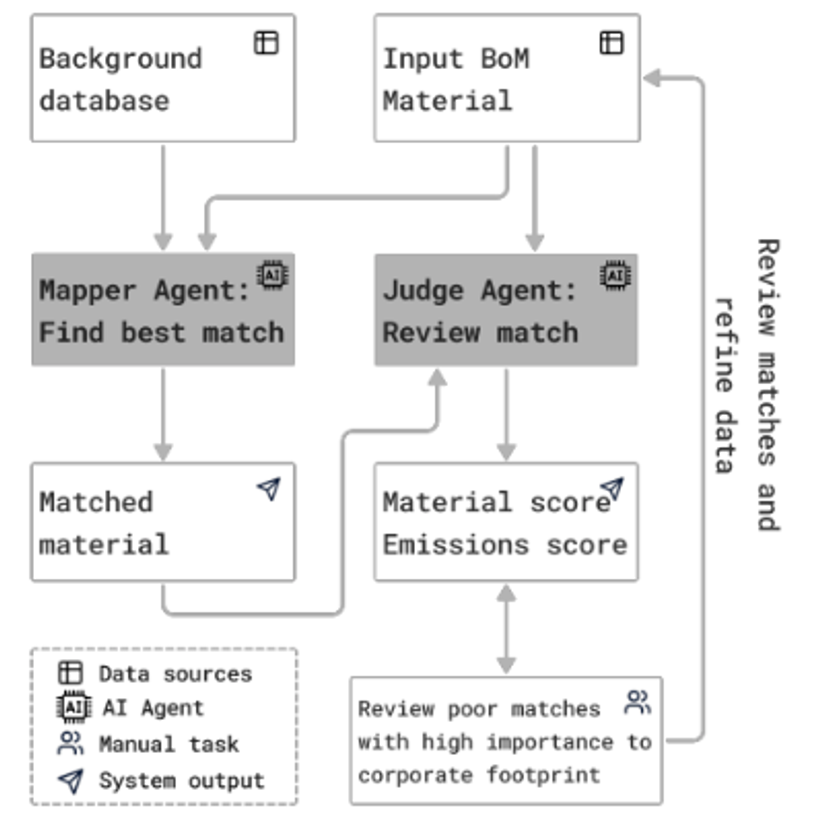
The auto-mapper has a dual-agent architecture to map materials to emissions factors:
The Mapper Agent takes messy procurement text ("304 SS sheet") and matches it to structured life cycle inventory databases using retrieval-augmented generation. It resolves ambiguity using context—like knowing the reporting company's industry.
The Judge Agent operates independently, scoring each match without seeing the Mapper's reasoning. This separation prevents overconfidence and ensures we flag low-quality matches for human review.
Where the judge determines a match is high quality—because the input is clear and has a good match in the database—the error rate was very low at only 0.3%. In a world without AI, these correspond to the mappings where there is the least subjective judgement and experts would be more likely to agree; with the AI, the results are strong and consistent, and possible in moments across thousands of materials.
For materials where there is a less obvious “answer,” the system is designed to flag and justify the approach in case the user wants to manually review the mapping or—if the AI’s explanation makes it clear there isn’t an appropriate match—consider a different approach like building a PCF that incorporates multiple EFs.
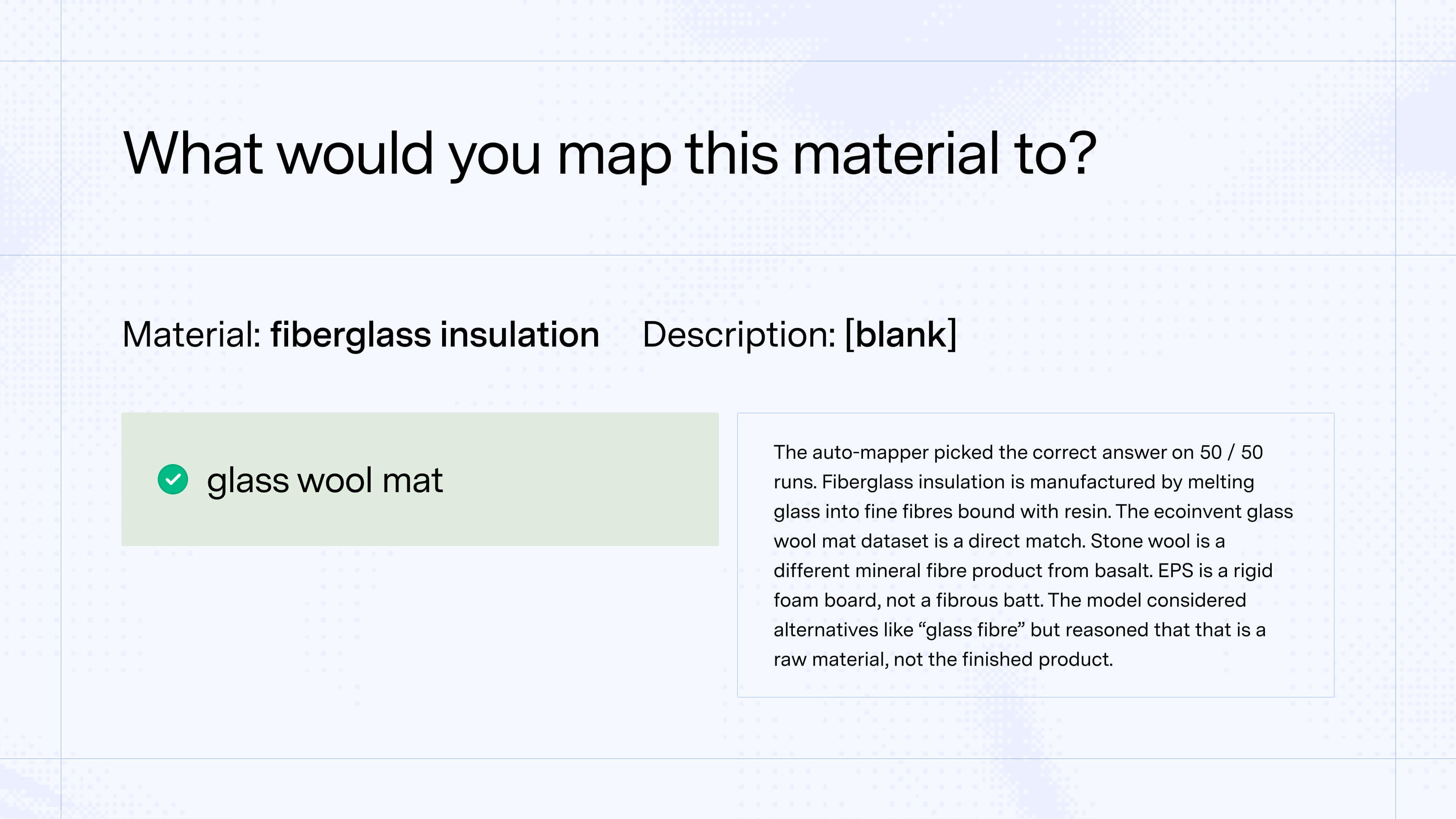
One common case where there isn’t as obvious an “answer” include cases where a material is more specific than the best-fit ecoinvent EF. For example, a hospital system might purchase high quantities of ibuprofen. In Watershed, the auto-mapper maps ibuprofen to “chemical, organic” as the closest fit in ecoinvent, sharing its reasoning:
“I chose "chemical, organic" because Ibuprofen is an organic chemical, and this is the most appropriate generic proxy available in the library when a specific match is not found. It aligns with the material family and the general nature of the input.
Alternatives considered: I considered other specific organic chemicals like "acetanilide" or "benzoic acid" because they are also organic compounds and some are used in pharmaceuticals. However, "chemical, organic" is a more appropriate and less misleading generic proxy.”
The outcome is what most experts would select as the “correct” mapping. For another purchased material—say, a catered sandwich with bacon, turkey, and vegetables—experts would vary on the mapping. Watershed similarly flags these mappings where there are multiple options that make sense, and assigns that it deems to be the best-fit with justifications that humans reviewing can understand.
With Watershed, these mappings are possible across all purchased goods in moments, with additional insight that helps to guide where a company could go deeper. For example, if ibuprofen had major purchase volume, the customer could go beyond the auto-mapper to run Watershed’s advanced AI model that creates bespoke, decomposable upstream PCFs accounting for supplier-specific nuance to drive better procurement.
Watershed’s auto-mapper achieved 98.9% defensible mappings
Our auto-mapper achieved 98.9% defensible mappings on the Amazon Parakeet benchmark dataset. For context, this dataset contains 275 material-to-emissions-factor mappings, primarily food products that Amazon's model labeled.
We also tested our auto-mapper against an expanded evaluation dataset with 1,039 materials that included Parakeet plus additional materials that represent more diverse and challenging data customers might encounter, like foreign language samples, vague material names, and other edge cases like:
- IP EVA (an abbreviation for ethylene vinyl acetate)
- M4x6ss (a stainless steel screw)
- SOJA EM GRAOS GRANEL (Portuguese for soybeans)
Our auto-mapper achieved 90.7% defensible mappings against this messier dataset. Within the expanded evaluation dataset, where inputs were well-specified (not vague descriptions like "plastic part"), performance was high across material types: 100% for catalysts, 95.6% for packaging, and 93.3% for our curated representative samples.
Benchmarking dataset | Materials included | N | Defensible mappings |
|---|---|---|---|
Amazon Parakeet | Primarily food products | 275 | 98.9% |
Expanded evaluation dataset | Parakeet + other external benchmarks, production data, and edge cases | 1,039 | 90.7% |
Repeatability is another important performance metric. Large language models (LLMs) are non-deterministic; in other words, users can put in the exact same input twice and get two different outputs. With the auto-mapper, we want the model to pick the “best” fit consistently and repeatably, especially when there is a relatively clear best-fit emissions factor. The auto-mapper does in fact perform well here: where there is a single unambiguous emissions factor match, repeatability approaches 100%.
Our climate scientists also found opportunities to improve Parakeet’s dataset
When our climate scientists reviewed the benchmark’s labels—the “answer key” for this test—they found opportunities to improve the dataset. In a few cases, the listed “correct” emissions factor didn’t seem defensible. For example, the material “turkey chili” was mapped to “chilli” in ecoinvent, which represents the vegetable, not the meat-based dish. Similarly, “evaporated milk” was mapped to “evaporation of milk” which actually excludes the milk itself, and “key lime” was mapped to “lime,” which in ecoinvent represents quicklime, a caustic solid used in construction.
In other mappings, the question itself had multiple reasonable answers, but the benchmark only credited one. For example, “rice” was mapped to “rice, basmati” while the “rice, non-basmati” was not accepted as an answer despite the rice type being unspecified.
When we updated those labels to account for incorrect or limited mappings and rebuilt the evaluation, our performance improved even more.
Benchmarking within emissions measurement is inherently difficult without ground truth — but benchmark datasets like Parakeet still help
In many AI domains, benchmarking is like grading a multiple-choice test: there is a clear “right answer” for each question. Emissions measurement is different. There is rarely a single, objective “ground truth” value for the actual emissions of a specific purchased good—because the real world is complex, and because we cannot fully instrument and observe every upstream process.
That means many mapping decisions could be thought of less like a multiple choice test and more like an essay: there is a grading framework, but expert judgement still plays a role, and reasonable experts may disagree (see this research study where six LCA experts tasked with making an LCA of an Italian red wine took highly varied allocation approaches).
This doesn’t diminish the value of carbon measurement. It means the goal is defensible measurements rigorous and consistent enough to guide real decision-making. In practice, activity-based emissions factors and PCFs are the best proxies available, despite the fact that two practitioners can still arrive at slightly different outcomes given the subjective choices involved.
Against that backdrop, public benchmarks like Amazon’s Parakeet are valuable because they give the industry a shared test to compare and validate approaches, and give buyers a concrete way to validate accuracy claims.
While AI has immense opportunity to level-up what’s possible with speed and accuracy of measurement, it requires climate science expertise in tandem to guide robust reviews and iteration. As we continue improving our auto-mapper, we're excited to share what we learn with the broader LCA and climate science communities to accelerate what’s possible in the field.
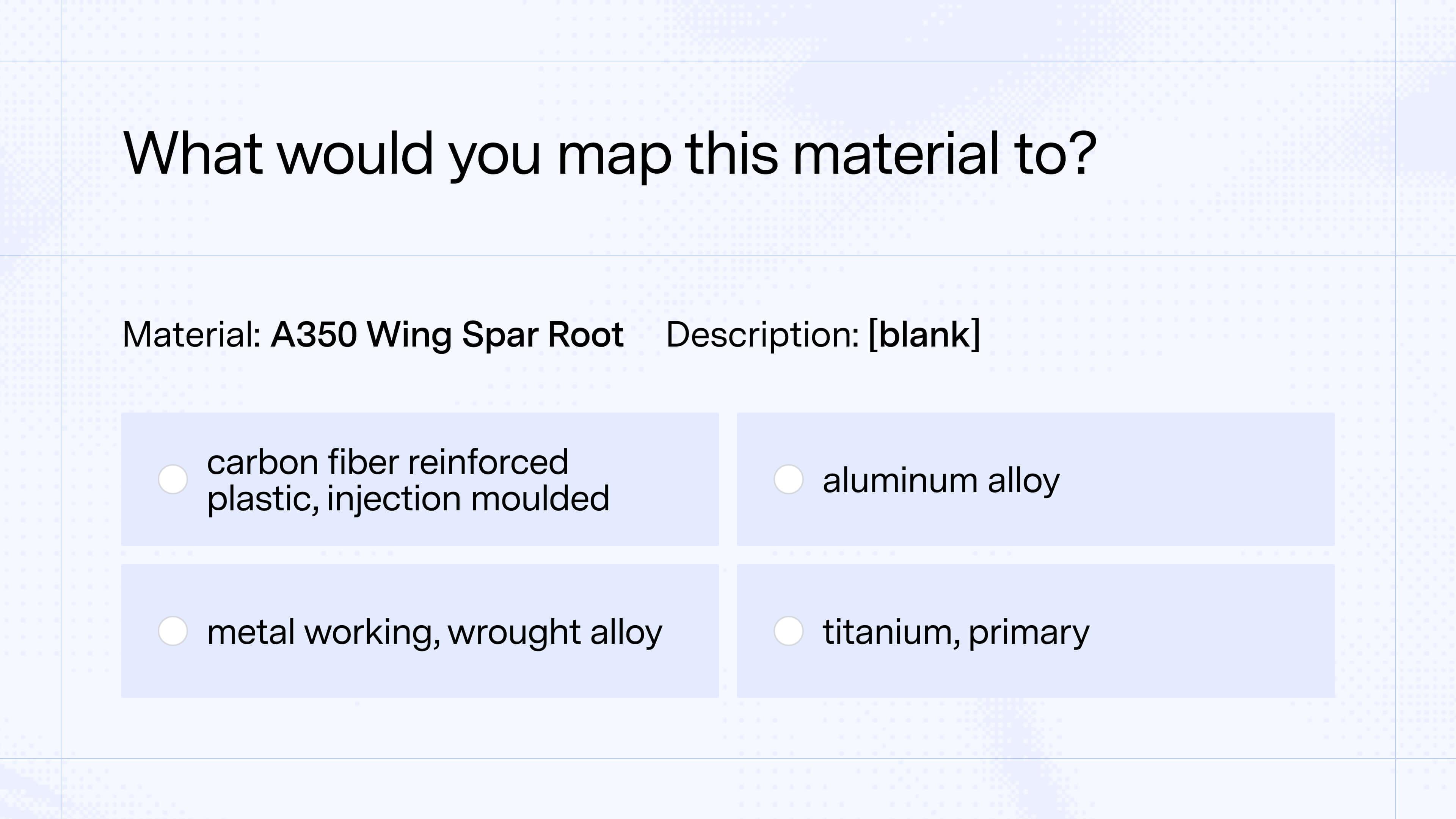
Curious to see how you’d stack up against auto-mapper?






Want to see the auto-mapper in action?
Watershed customers can automatically map materials to activity-based emission factors, with quality scores highlighting which mappings need human review. And — for materials where no suitable EF exists, customers can build product footprints with our advanced AI model to decompose the material’s full supply chain for a more accurate, actionable measurement.