By Carl Jackson
Watershed helps businesses run world-class climate programs. One part of this is helping them model what their emissions will look like in the future. This helps them understand if making a climate commitment is feasible, or how an emissions reduction might change what their climate impact looks like in the future.
In order to help our users with this, Watershed has built a sophisticated model for forecasting a business as it grows over time. It takes into account their existing carbon footprint, the business's projections of the growth of its key business metrics, a growing library of Watershed's vendor projections, and the user's custom reduction initiatives, among other factors. If you're familiar with building forecasts in a spreadsheet this forecasting model will feel familiar, but it's an order of magnitude more configurable than any spreadsheets we've seen before.
Our forecast is built into the Watershed dashboard, but just like a spreadsheet we wanted the forecast to feel interactive and playful. We wanted users to be able to quickly experiment with ideas, and to get instant feedback from the charts and tables on the page.
Problems with React’s useMemo
We initially built the feature by calculating the forecast in a React component's render function, but quickly ran into performance problems: for our largest users, computing the forecast took a second or more, making the page unusable. At Watershed, we always start with the simplest solution, so our first solution was to use useMemo, a React hook that memoizes a piece of computation. By carefully splitting up the work into small useMemo blocks we were able to make the page feel snappy again, but at a cost. We encountered two problems: what I'm calling the "taint problem" and the "modularity problem."
The taint problem is a common useMemo gotcha. useMemo has a very primitive dependency tracking system—it re-calculates a given function whenever its inputs change (based on referential equality). Unless every dependency of a useMemo block is itself memoized, it might change on every React render, causing the useMemo’d function to recompute every time. That is, a single un-memoized value will taint every computation downstream of it, negating the benefits of memoization. Worst of all, this occurs silently, without warnings to the programmer. Our forecast model regularly had performance regressions caused by accidental un-memoized computations.
The modularity problem is more subtle. We use the forecast model on several pages across the Watershed product, and each page needs different parts of the forecast (e.g., projecting next year’s Cloud emissions, or getting business-wide statistics for the next 10 years). Ideally, the parts of the computation would be modular, and we’d be able to calculate exactly what each page needed and no more. But the React hooks programming model is eagerly evaluated and doesn't allow branching, which makes it hard to evaluate only some (but not all) of the useMemo blocks in a larger model. We tried a few ideas—like boolean flags and nullable computation outputs—but those “fixes” often made our code harder to understand. Except for a few places where performance was critical, we mostly weren’t able to modularize our forecast model; instead we computed the entire thing each time.
Incremental computation
When our simple solution was no longer enough, we decided to invest in a replacement. We decided to rethink our programming model to turn these performance concerns into a pit of success.
Our solution was to write an incremental computation library. This library keeps track of which parts of a computation depend on which other parts, and when the inputs change, avoids recomputing any values that couldn't have been affected. If you've ever used a spreadsheet, this is similar to how modern spreadsheets are implemented
Getting incremental computation right is hard, and we were glad to learn from the experience of several folks who have spent a long time thinking about this problem. The best overview article we're aware of is Robert Lord's "How to recalculate a spreadsheet." We based our implementation off of Jane Street's Incremental, which Ron Minsky gave an excellent talk about. If you'd like to learn more, we highly recommend both Robert's blog post and Ron's talk: their explanations are clear and insightful.
In our implementation there are two types of values: Variable and Calculation, which represent input data and computations, respectively. Calculations can depend on the values of Variables, other Calculations, and any other part of your JavaScript codebase, and are only recomputed when a dependency Variable or Calculation changes its value.
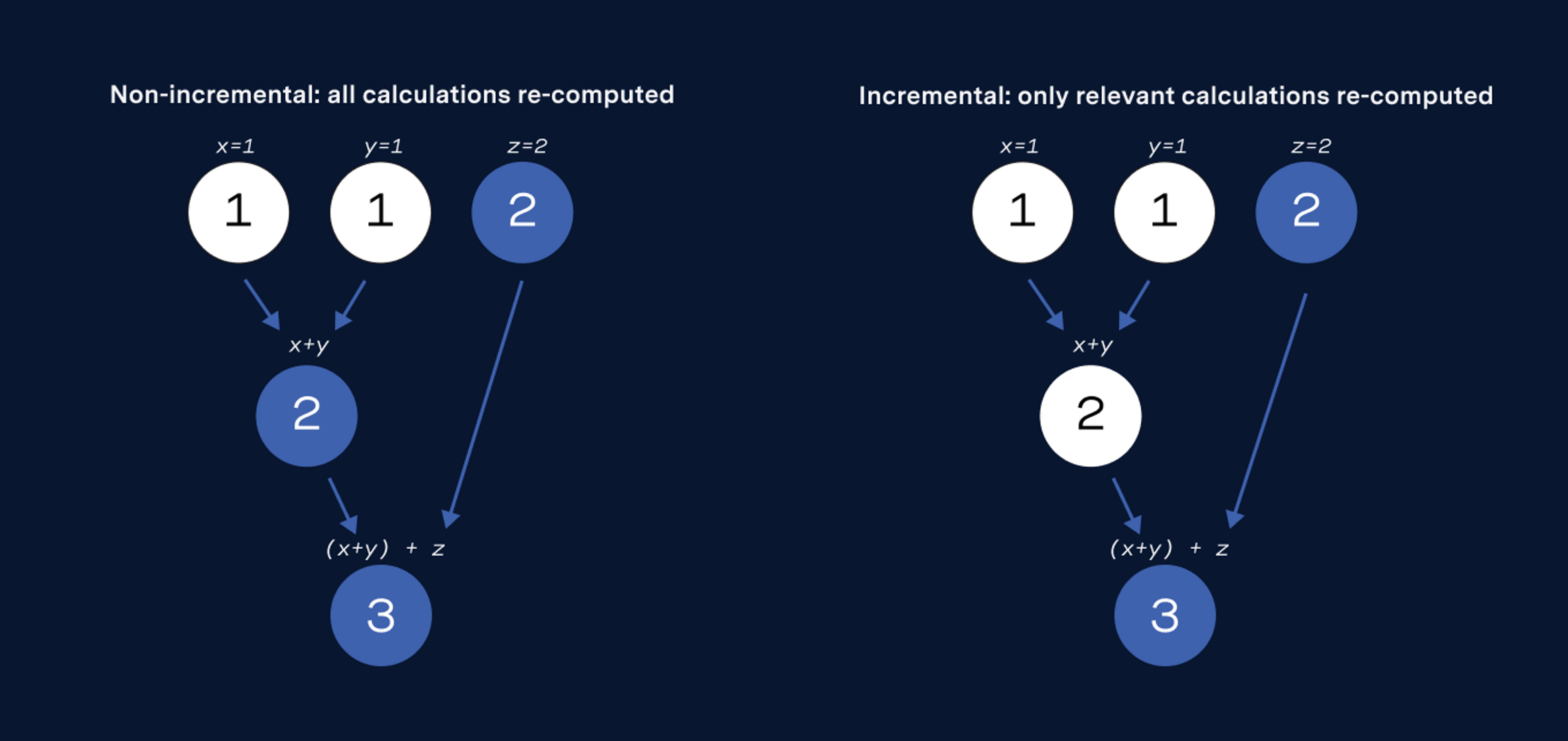
Our incremental computation library provided the conceptual building blocks of a solution to our useMemo problems. To make it easy to work with, we built a simple interface to it we call XModel (the "X" stands for "Excel," a hat-tip to the spreadsheet versions of several of our early products, including the forecast model). By adding a small number of decorators into a normal JavaScript class, XModel gives engineers an ergonomic way to make their code update incrementally.
Here's an example of what an XModel might look like in practice:
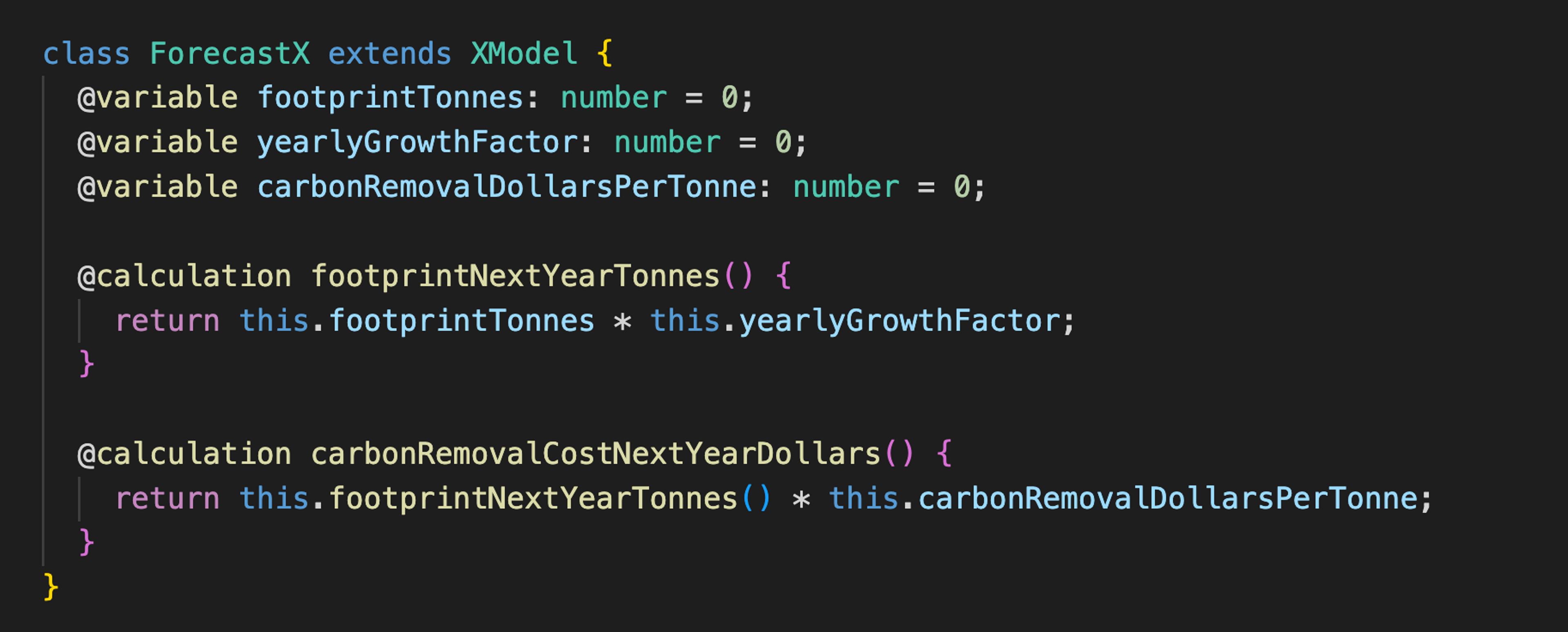
If you're familiar with Javascript, it's easy to understand what this code does: just ignore the @variable and @calculation decorators, and read the rest of the code as-is. Behind the scenes, the XModel library uses the decorators to define getters and setters for underlying Variables, and wraps each method in a Calculation, but engineers don't need to understand any of that to be productive.
In addition to the XModel class, we've also developed a set of React hooks that allow React components to depend on parts of an XModel, and to automatically re-render when those parts change.
Circling back to our original problems with useMemo, has XModel and incremental computation helped with our forecast model performance issues? Yes! Performance used to be a twice-a-month fire drill for the team, but after switching to XModel it hasn't been a concern.

The taint problem is completely gone: @calculation always understands its dependencies and memoizes its results, so it's impossible to accidentally de-optimize a computation. A method that is missing a @calculation decorator will simply miss out on additional optimizations.
The modularity problem has been solved by lazy demand-driven evaluation in the XModel programming model. That is, since XModel explicitly tracks which parts of the forecast are currently being used on-page, and can trace those computations back to their inputs, it always knows precisely what to calculate (or re-calculate). And because nothing is required of the programmer to manage the data dependency graph, we’ve found that the resulting memoized computations tend to be smaller, further increasing both code quality and performance.
Conclusion
XModel and incremental computation have allowed us to scale our business forecast model to new features and to businesses with more data than we originally thought possible, all while keeping a great instant-updating user experience. And we've done so while decreasing the cognitive burden of writing compute-heavy code—in fact, all of the features in the past six months have been without engineers having to think hard about performance or memoization.
This is just one of many engineering problems we’ll need to solve as we help decarbonize the economy. Want to join the fight against climate change? Come join us!